↑ “凹凸数据” 关注 + 星标 ~
每天更新,大概率是晚9点

这次终于将“罪恶”的小手伸向了APP
下面有请今日的爬虫师——
大家好,我是银牌厨师豆腐!
最近群里很多小伙伴对爬取手机app和小程序感兴趣,今天本厨师将给大家呈现这道菜,供小伙伴们品尝。
相信大家都对爬虫有一定的了解,我们爬PC端时候可以打开F12去观察url的变化,那么手机的发出请求我们应该怎么拦截呢。
今天的主菜就是给大家介绍一个抓包工具Fiddler,并用它烹煮一道广州房价爬虫。
Fiddler是一个http调试工具,也仅限于拦截http协议的请求,这是它的短板之处,但是对于我们平常的练习运用也足够了,因为大多数网站都是走http协议。跟Fiddler同类型的抓包工具还有很多,像Charles、Burpsuite等等
像其中Burpsuite的功能是比较强大的,它们都是PC软件,不是装在手机端,有兴趣的小伙伴可以去了解一下
抓包工具Fiddler
话不多说,我先教大家怎么设置Fiddler。
主要三个步骤:
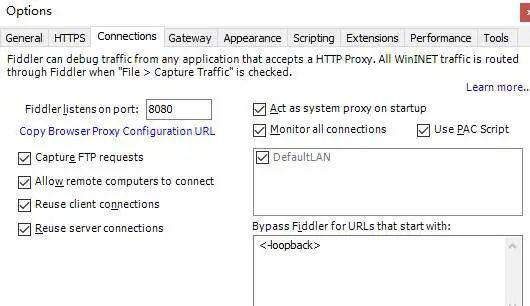
1、安装软件后,打开Fiddler的Tools选项,进行第一步,分别对General,HTTPS,Connections窗口进行如下设置
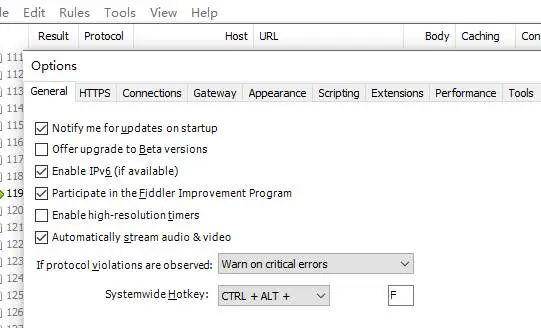
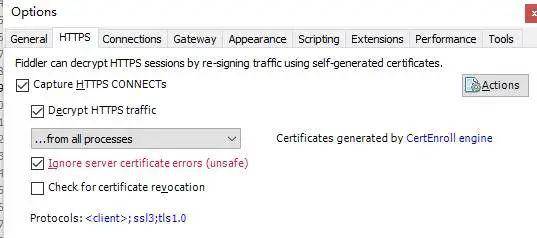
把该勾上的勾上后,我们回到HTTPS这个界面,点击Actions,选择Trust,安装证书,
这时候我们的PC端的洗菜流程已经完成啦
2、接下来我们就要设置手机端,我们既然要通过PC端拦截手机发出的请求,就要设置手机的网络跟PC是同一个
网络下,所以第二步,我们要更改手机ip。我们先来看看你的PC断ip是多少。先打开cmd进入终端后,输入ipconfig回车
就可以看到你的ip地址了
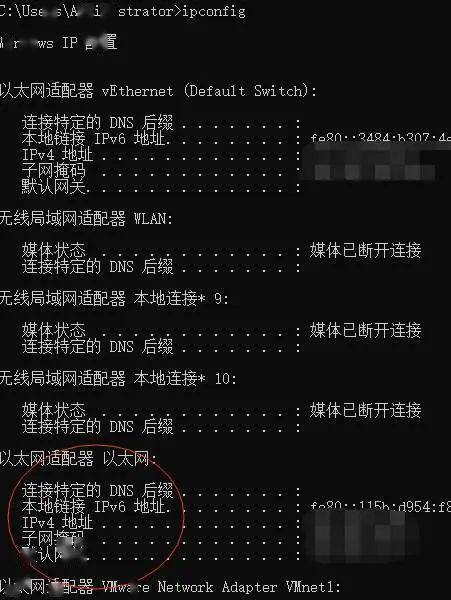
这时候终于轮到你的宝贝手机出场了,熟练的连上你的wifi之后,修改你的wifi设置,点击高级选项后,分别输入你的ip和端口后保存。
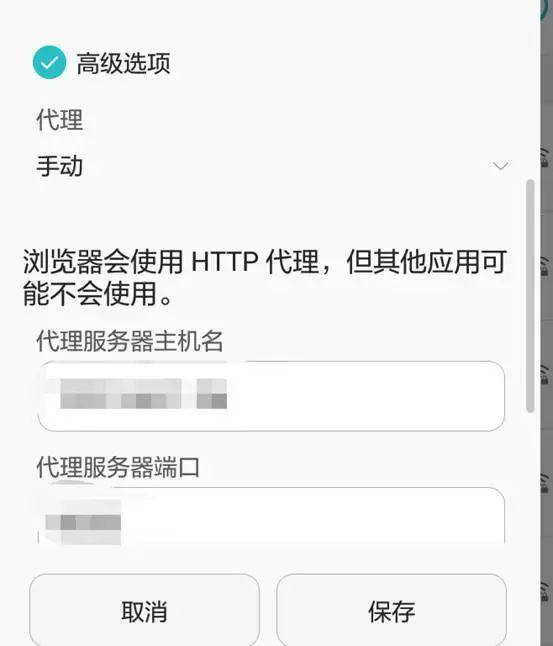
3、大家是不是觉得很简单呢,别高兴太早了!最关键的一步到了,在我们完成第一、二步设置后,打开你的手机浏览器输入你的ip和端口号(例127.0.0.1:8080),回车,这时候会跳转到一个下载手机端证书的页面,下载后并信任证书后(注:某些安卓手机会要获得root权限才行),这时候,我们安装三部曲就大功告成了。
万事俱备,只欠东风,食材都清洗好了,现在我就教大家怎么利用Fiddler烹煮小程序。
抓包实战
先打开一个小程序网站,我选择的是Q房网,大家看,菜下锅后,Fiddler是不是变化了。
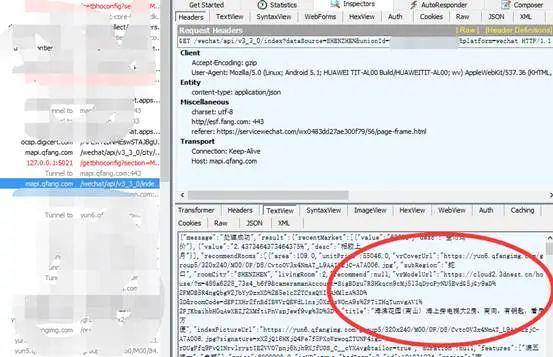
这就是用fiddler拦截到你的手机发出请求的网页信息了和它的链接,这个网页信息是通过json数据加载的
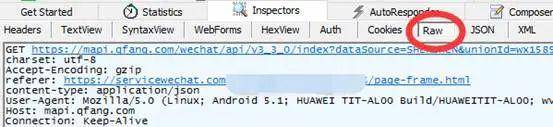
然后往上看,Raw模块是获取请求头的地方
有了这两个信息,我们的爬虫代码也就可以开始编写了
爬虫代码
基操requests,循环页数,由于是获取的数据是json格式,我们就要利用json.loads格式化抓取的信息,才能进行一个数据提取。
部分爬虫代码,完整版下载见文末
url = 'https://mapi.qfang.com/wechat/api/v3_2_0/room?dataSource=GUANGZHOU&unionId=这里也是微信id&platform=wechat&bizType=SALE¤tPage={}&pageSize=20&keyword=®ion=&l=&s=&p=&b=&a=&r=&h=&g=&t=&o=&fromPrice=&toPrice=&unitPrice=&fromUnitPrice=&toUnitPrice='
#爬取到50页,程序就停止
fori inrange( 1, 51):
time.sleep(rand_seconds)
url3 = url.format(i)
# print(url3)
res = session.get(url=url3, headers=headers)
# print(res.text)
data = json.loads(res.text)
try:
id_list = data[ 'result'][ 'list']
# print(333,id_list)
fori inid_list:
id = i[ 'id']
# print(id)
url2 = 'https://mapi.qfang.com/wechat/api/v3_2_0/room/detail?dataSource=GUANGZHOU&unionId=这里也是微信id&platform=wechat&id={}&bizType=SALE&userId=&accountLinkId=&top=1&origin=sale-list'.format(
id)
time.sleep(rand_seconds)
try:
requests.adapters.DEFAULT_RETRIES = 3
res2 = session.get(url=url2, headers=headers, timeout= 10)
exceptrequests.exceptions.Connecti:
requests.adapters.DEFAULT_RETRIES = 3
res2 = session.get(url=url2, headers=headers, timeout= 10)
exceptrequests.exceptions.ReadTimeout:
requests.adapters.DEFAULT_RETRIES = 3
res2 = session.get(url=url2, headers=headers, timeout= 10)
item = {}
res2_data = json.loads(res2.text)
try:
roominfo = res2_data[ 'result'][ 'roomInfo']
exceptKeyError:
break
爬取数据结果:

数据可视化
菜做好了,当然还要撒点香菜才能上桌啦,做个简单可视化吧,由于爬取的数据很干净,我省掉清洗数据的环节,直接上手,在各位群大佬面前献丑了。
我们先来看看该网站的广州二手房的最高价和最低价,这最高价的数字太感人了.... 这多少个0我都数不对
importpandas aspd
importmatplotlib.pyplot asplt
df = pd.read_csv( r'F:PycharmProjectshouse_spider广州二手房.csv', encoding= 'gbk')
# print(df)
df = df.astype({ 'price': 'float64'}) #先将价格的类型转为浮点数,方便后面计算
df_max = df[ 'price'].max #查看爬取的数据中房价最高的价格
df_min =df[ 'price'].min #房价最低的价格
print( '广州二手房最高价:%s,最低价:%s'%(df_max,df_min))

re_price = [ 'region', 'price']
# 分组统计数量
price_df = df[re_price]
# #根据区域价格计算区域房价均价
region_mean_price = price_df.groupby([ 'region'],as_index= False)[ 'price'].agg({ 'mean_price': 'mean'})
region_mean_price = region_mean_price.sort_values(by= 'mean_price')
print(region_mean_price)
#利用循环提取已经处理好的区域和它的均值
forx,y inzip(region_mean_price.region, region_mean_price.mean_price):
plt.text(x, y, '%.0f'%y, ha= 'center', va= 'bottom',fontsize= 11)
# 显示柱状图值
plt.bar(region_mean_price.region, region_mean_price.mean_price, width= 0.8, color= 'rgby')
plt.show
继续继续,我们来统计一下广州各区的房价,然后算出各个区域均值,通过groupby分组统计出region_mean_price
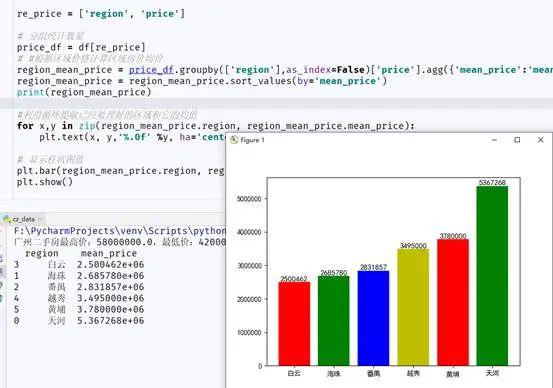
(豆腐内心os:原来黄埔房价都那么高了,各网站数据的差异性也会导致最终展示的结果不一样,大家可以选个大网站试试)
到此,我们这次利用工具抓包小程序网站的介绍就结束了,大家也可以试试app,原理一样。
谢谢大家观看,拜拜咯~
本文涉及爬虫、可视化代码下载:
https://alltodata.cowtransfer.com/s/f0b70e0c24164c
责任编辑:
