新酷产品第一时间免费试玩,还有众多优质达人分享独到生活经验,快来众测,体验各领域最前沿、最有趣、最好玩的产品吧~!下载客户端还能获得专享福利哦!
本文来自快科技
这几年,国产CPU处理器突飞猛进,而且在不同架构上齐头并进,包括x86架构的兆芯、海光,MIPS架构的龙芯、君正,ARM架构的飞腾、鲲鹏,Alpha架构的申威,RISC-V架构的阿里玄铁等等。
其中,海光(Hygon)是一个非常特殊的存在,因为他居然拿到了AMD的官方授权(注意不是技术转让),而且是大获成功的最新Zen架构,在性能方面是最值得期待的,但到底能达到什么程度一直扑朔迷离。
最近,权威硬件评测网站AnandTech拿到了海光处理器,包括8核心的桌面版Dhyana、32核心的服务器版Dhyana Plus,进行了深入分析和测试。

一、AMD和海光的复杂合作
其实,海光能获得AMD x86架构授权是非常曲折的。虽然美国政府对此大开绿灯,但为了规避Intel专利限制和相关法律,绕了一个大圈子:
AMD、天津海光信息技术有限公司(天津海光)作为两家主体合作公司,通过合资的方式成立了两家新的公司,一个是成都海光微电子技术有限公司(海光微电子),另一个是成都海光集成电路设计有限公司(海光集成电路)。
海光微电子由AMD主要控股51%,拥有AMD授权IP(知识产权)并负责芯片生产,海光集成电路则由天津海光主要控股70%,负责芯片设计与销售。
而一颗海光处理器的诞生,可以分为11个步骤:
1、AMD将核心设计授权给海光微电子,并提供建议的SoC布局
2、海光微电子向海光集成电路提供芯片设计平面图
3、海光集成电路将修改建议反馈给海光微电子
4、AMD工程师审核修改建议,予以批准或否定
5、海光微电子将最终设计平面图返回给海光集成电路,并准备接订单
6、海光集成电路向海光微电子订购晶圆、硅片
7、海光微电子联系GlobalFoundries进行代工制造
8、GlobalFoundries按照设计达成预定频率/电压、良品率
9、海光微电子将完整硅片卖给海光集成电路
10、海光集成电路在中国国内完成硅片封装
11、海光集成电路在中国内地市场销售成品处理器
是不是绕晕了?没办法,想获得最先进技术,就是这么难。

特别注意的是,海光获得的只是AMD 14nm Zen架构的IP授权,而不是完整的技术转让,底层设计和技术、专利依然属于AMD,海光只能在高级层面根据自己的需要进行修改、定制。
打个比方,技术转让相当于买了块地皮,你就是房地产商,可以自己规划盖高楼,想怎么盖就怎么盖,ARM架构的华为麒麟等就是这种。
IP授权相当于买了个毛坯房,你只是业主,可以自己装修、安装家具,但不能改变楼房结构,墙壁里安装个窃听器你也没办法。
并且,AMD授权的也不是完完整整的Zen架构,而是阉割后的残血版,性能和锐龙、霄龙相比不在一个层次上,所以对后边的测试成绩要做好心理准备。
但无论如何,你付了钱买了房子,你就是主人,所以海光确确实实是一款国产处理器,而且能对如此复杂、先进的x86架构吸收并改进设计,并不是谁都能做到的。

采用海光处理器的曙光工作站
二、海光Zen架构的阉割与修改
海光并非直接把AMD Zen架构芯片拿过来打磨改个名,AMD也没这么大方,一方面允许自行修改设计,但另一方面也在架构规格上做了不少精简。
这方面没有任何官方资料,AMD、海光都异常低调、守口如瓶,但是通过各种分析检测,AnandTech还是发现了很多秘密。
1、基本架构不变
海光处理器在核心布局上和原版Zen完全相同,缓存容量、TLB容量、端口布局等都没变,比如一级指令缓存4路64KB,一级数据缓存8路32KB,二级缓存8路512KB,三级缓存16路8MB。
测试显示,内存访问时间一级缓存4个周期、二级缓存12个周期、三级缓存37-40个周期,内存延迟284-307个周期。
一级缓存读取速度每核心约100GB/s,写入速度约51GB/s。八核心的DDR4内存读取速度38.5GB/s,写入速度35.8GB/s。
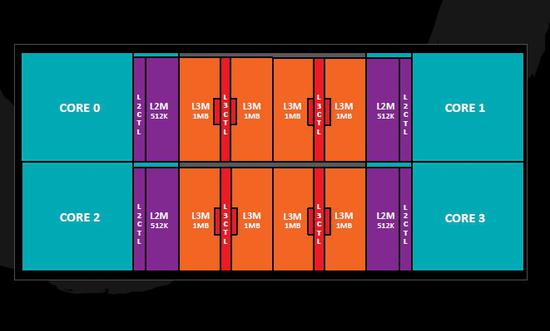
Zen架构内核简图
2、新的加密机制
出于安全考虑,海关在这方面做了大刀阔斧的改变。
Zen架构的霄龙中有AMD SEV虚拟化加密技术,涉及RSA、ECDSA、ECDH、SHA、AES等加密算法,海光则改成了我国自己发布的SM2、SM3、SM4,更有可控性。
SM2是椭圆曲线公钥密码算法,相比于RSA更先进、更节能、更安全,国家密码管理局2010年12月17日发布。
SM3是哈希算法,属于密码散列函数标准,用于数字签名及验证、消息认证码生成及验证、随机数生成等,原理、安全性和效率都类似SHA-256,国家密码管理局2010年12月17日发布。
SM4是分组密码算法,用于数据加密,分组和秘钥长度都是128位,类似AES-128,国家密码管理局2012年3月21日发布。
Linux内核也加入了相应的指令,以支持这些加密算法,不过有趣的是,他们不但在海光处理器上测试成功,AMD霄龙上也能运行。
3、指令集大缩水
这是AMD下手最狠的地方,大量指令要么把速度降了下来,要么直接砍了,对性能影响非常大。
测试发现,海光获得架构的整数性能基本没变,但是浮点性能损失很大,DIV、SQRT等浮点指令直接消失,大量的MMX/SSE简单指令则被降速:
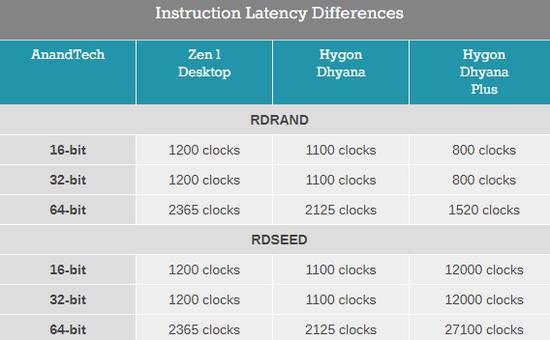
这些都是基础指令,对于日常基本性能至关重要,速度变慢直接就把实际性能给拉了下来。
另外,桌面版Dhyana、服务器版Dhyana Plus的差别也很大,比如至关重要的随机数生成算法,就在服务器版上严重削弱。
RDRAND算法在海光这边其实更快了,服务器版上更是快得多,RDSEED算法在海光桌面上也加快了,但服务器上慢了足有10倍之多。
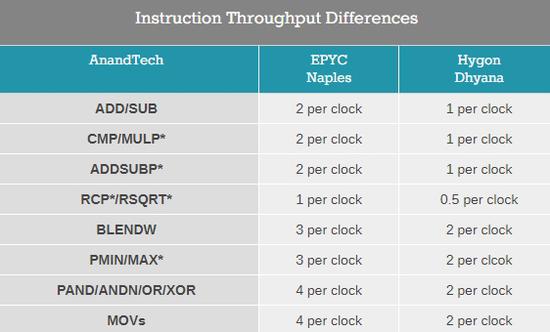
事实上,二者都可以在海光的BIOS里选择开启或关闭。
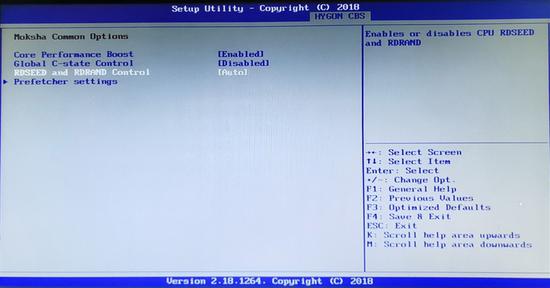
AVX、AVX2指令集也很奇怪,检测显示海光是支持的,但似乎已被禁用,相关测试根本无法运行,AESNI、SHA、CLMUL、FMA4、BMI、BMI2等指令无一例外。
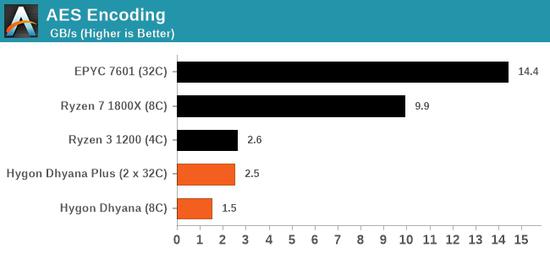
缺少这些指令会影响到什么程度呢?比如AES编码,两颗32核心的海光竟然都跑不过入门级的4核心锐龙3 1200:
三、海光处理器就长这样
说了半天,是时候请出本尊了。

这是一个8核心海光桌面处理器的工程样品,表面印有HYGON中科海光的标识,“用芯计算未来”的口号,还能看到成都封装字样,但没有具体型号和规格。
C86应该是代表China x86。

不同于AM4独立封装的AMD锐龙,海光采用BGA整合封装,直接焊接在主板上,无法更换和升级,辅以简单的6相供电,不过奇怪的是,散热器安装孔距并非AMD AM4规格,而是Intel的。
整体板型为mciroATX,供电接口有24针主供电、8针辅助供电和D形大4针辅助供电。还有两块电池,一块显然是保存BIOS,另一块未知。
两条内存插槽位于处理器上方,典型的服务器布局以方便散热,另有四个SATA 6Gbps磁盘接口、两条PCIe 3.0 x16和一条PCIe 3.0 x4扩展插槽。
海光其实也是SoC,为了扩展输入输出搭配了一颗Lattice Semiconductor FPGA,提供SATA接口、四组LED指示灯和各种定制接口、插针、按钮。
集成GPU当然没有,使用的是服务器上常见的IPMI控制器和ASPEED AST2500芯片,提供简单的2D图形输出。

放上去一颗锐龙处理器,尺寸是完全一样的。

这是32核心的海光服务器版本,外形尺寸和线程撕裂者、霄龙几乎一模一样,也有保护支架,同时表面可以看到7185的型号标识,其他类似桌面版。


服务器整机来自曙光,面向计算和存储市场,双路共计64核心,每路支持4块U.2硬盘、16块SATA硬盘,内存支持八通道,但本次测试因为一些限制跑的是四通道。
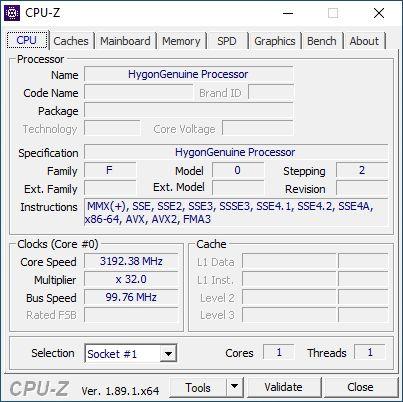
CPU-Z软件还不支持海光,服务器版直接无法运行,桌面版也只能检测出极少量信息,比如八个核心、3.2GHz主频,但奇怪的是,指令集里显示有AVX、AVX2、FMA3,但实际测试却无法用上,至少目前还没找到能利用的方法。(其实应该用AIDA64检测的,去年已支持海光。)
四、终于要跑分了
测试中,8核桌面海光搭配Windows 10专业版,双路32核服务器海光搭配Windows 10企业版,但由于AVX、AVX2指令集不正常,很多测试无法跑,项目有限。
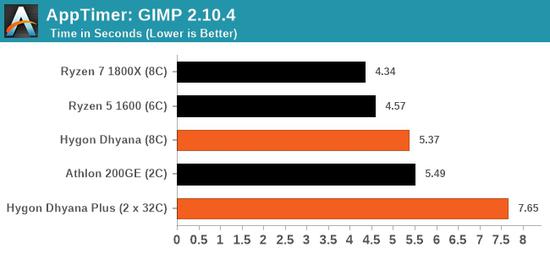
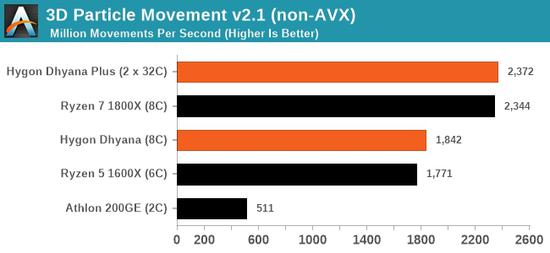
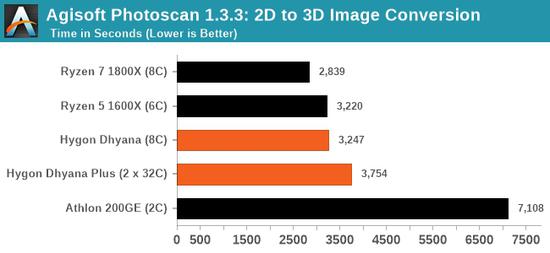
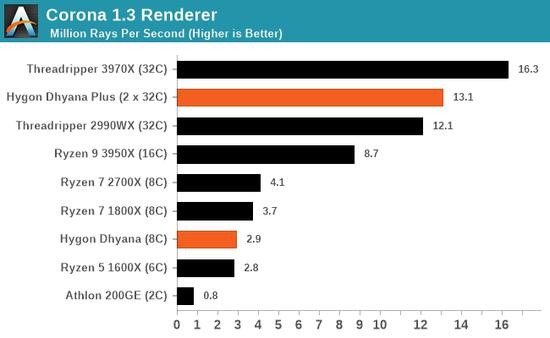
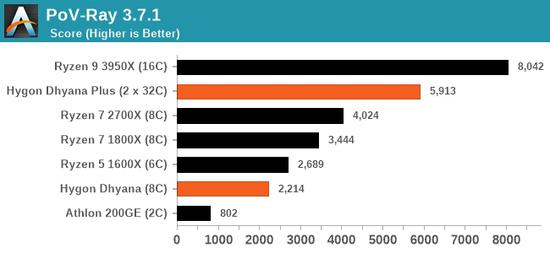
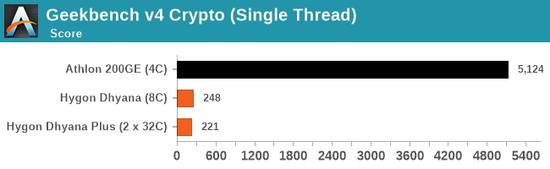
8核海光的性能大致类似6核锐龙5 1600X、8核锐龙7 1800X,但在特定测试中甚至可能还不如双核速龙200GE,比如最后一项GeekBench 4单线程加密性能。
双路32核海光的表现一团糟,很多时候还不如锐龙7 1800X,当然更没法和锐龙9 3950X甚至是撕裂者相比,唯一较好的就是更突出整数性能的Corona,可见浮点指令集削减造成的严重影响。
五、难得机遇 意义非凡
可能看完跑分,大家会感到非常失望,坦白地说乍一看确实也有点出乎意料,但其实也是合情合理的。
x86 CPU架构作为Intel、AMD两家美国巨头的核心资产,是绝对不会轻易外泄的,尤其是Zen这样非常成功的最新架构,按照一般逻辑我们能拿到手的可能性应该是零,以往想都不敢想,但是在各种因素的促成下,它确确实实到了我们手中。
AMD对海光的架构底层开放程度到底是什么层次,我们不得而知,但确确实实整套搬了过来,尽管规格上有些缩水但并没有本质性的削减,而且允许海光自行修改、设计(尤其是敏感的安全加密),已经足够我们的科研人员研究很久很久了。
可以说,这是一次空前难得的历史机遇,可以让我们一窥最新、最先进的集成电路设计,获得极为宝贵的经验,这次的合作模式也值得思考和借鉴。
可能在未来很长时间里,都不会再有这样的机会了,至少AMD已经明确表态,后续的Zen 2/3/4等等无意继续授权给海光。
整体来看,无论是桌面上还是服务器上,海光处理器的性能确实很平淡,毕竟指令集等关键特性做了大幅度的削减,对于这么先进架构的研究、优化也需要时间。
但是海光处理器的意义,绝不是达到多高的性能,而是有了一个全新的开端和突破。对于一些特殊、敏感的行业和领域,目前需要的也不是绝对高性能,而是首先解决有无的问题,解决能用的问题。
而且我们还有兆芯,来自威盛的x86技术,虽然架构技术相对Intel、AMD差了很多,但是在我们手里的自由度更大,满足一些特定需求是毫无问题的,甚至已经开始向零售市场渗透。
路,总是要一步一步走的,只要坚持走下去,就有希望,就有未来,更何况,我们的路还不止一条。

